这不是一个工作流,是一份 30+ 个 ComfyUI 工作流的横向拼接套件——位于 ComfyUI_windows_portable/ComfyUI/user/default/workflows/,过去半年里跨 6 个主题、5 个上游模型生态、多次迭代沉淀下来。
6 个主题:
- 基线出图:
zImageTurboBase_v60/下 GGUF / bf16 双轨,同 LoRA 堆同 prompt 在两份模型上对照质量 vs 显存。 - 单张分镜 + ColorMatch:把「分镜逻辑」与「色调家族」拆开,后期只改 ColorMatch 就能换品牌场景。
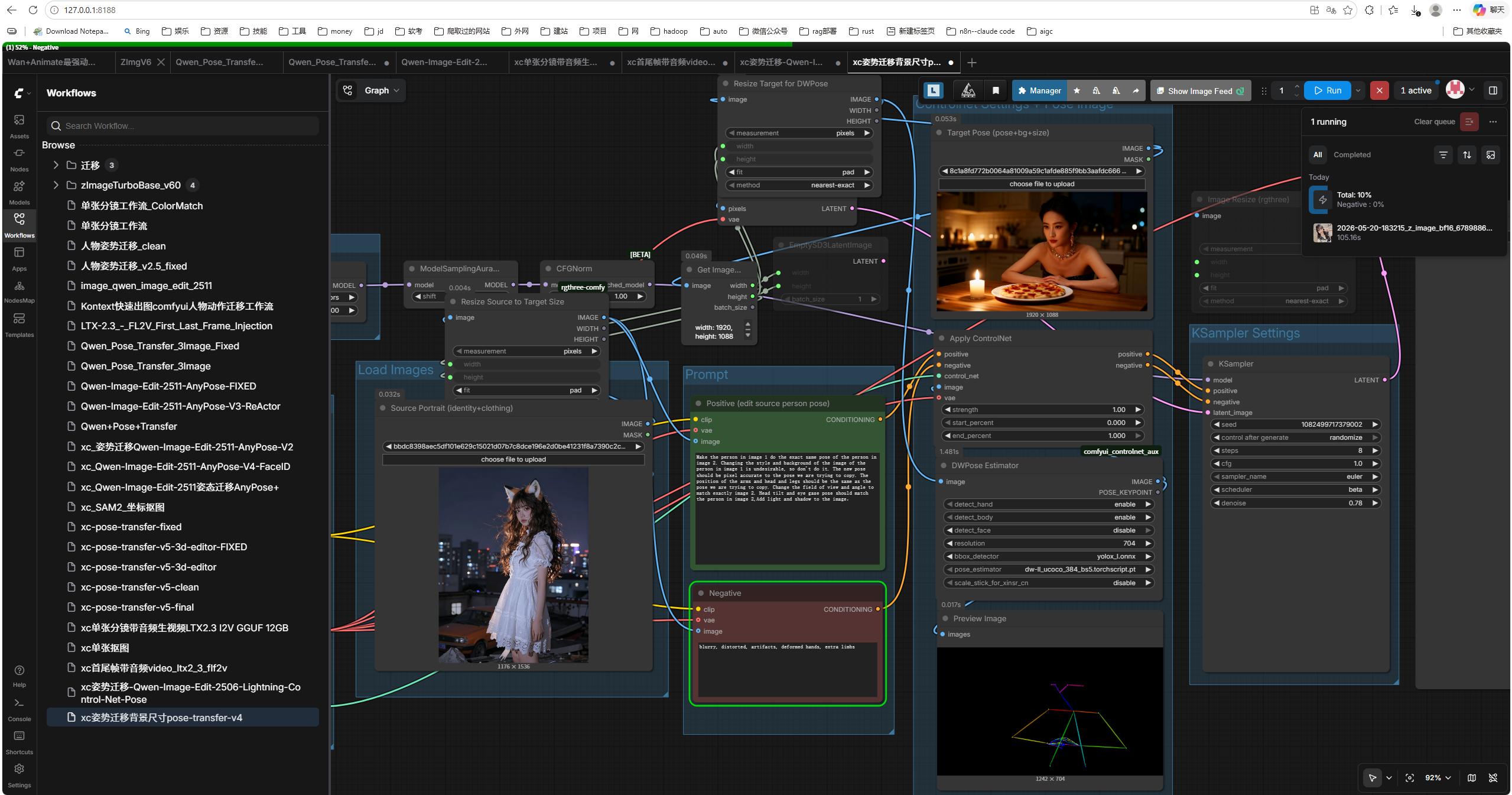
- 姿态迁移:从
人物姿势迁移_clean.json起,经 xc-pose-transfer v1→v5 五代、又转到 Qwen-Image-Edit 2511 AnyPose V2 → V3 ReActor → V4 FaceID 三代,共五代基础迭代,全代并存不被覆盖。 - Kontext 多图参考:Flux Kontext + StyleModel + CLIPVision + Nunchaku INT4 + ImageConcatMulti + 3 串联 KSampler,定位「快透透出图」。
- SAM2 9 节点抠图:坐标点击式,9 个节点串完——抠图从「调重复参数」退化为「这里点一下」。
- LTX 2.3 I2V 带音频:首末帧注入 + 音视频 latent 拼接 + GGUF 12GB 定点版。
5 个上游生态共存:Qwen-Image-Edit 2511 / Flux Kontext / LTX 2.3 / Wan Animate / SAM2。不绑定任何一家,各担一面。
12GB 显存约束被翻译成设计约束:所有主力工作流提供 GGUF 双轨;Wan Animate 用 BlockSwap 跳块加载;Kontext 上 Nunchaku INT4 加速;LTX I2V 明示标「12GB」。让「这套能不能跑」从「赌云 GPU 可用率」变成「本地几分钟出一张」。
「同参考图 → 静帧 → 视频 → 抠图」端到端:Hero shot 被设计为跨工作流可复用的「身份锚点」,Qwen LoRA 堆在工作流之间不重堆,颜色 / 艳度 / 背景质感在不同工作流间能被识别为同一个主体。
这一套的真正交付物不是 30+ 个 JSON 文件,而是一份沿同一审美约束、跨多模型、多代迭代后能并排对照的判断库——每个工作流都是一次「为什么这样组合节点」的可执行表述,JSON 一旦存盘,审美判断就不会随口头描述变模糊。
配图说明:封面与详情主视觉是 zImageTurboBase v60 在 bf16 模型上的基线出图;process 步骤里穿插了 Qwen-Image-Edit 2511 AnyPose 姿态迁移成品和 LTX 2.3 I2V 起始帧——以同一套件的真实输出展示「同一审美在不同工作流上的延续」。


